
The current paradigm in the clinic is that the maximum therapeutic benefits are obtained by killing the greatest possible number of cancer cells. The premise is that the larger is the induced cell kill the lower is the risk of developing drug resistance, an analogy made by experiences in the war against bacteria using antibiotics. That is why in general chemotherapy (as well as other cytotoxic drugs) is being administered in the maximal tolerable dose (MTD) regime. Obviously MTD assumption limits amount of patient-specific information that is being utilized in the treatment protocols as cancer-specific MTDs are being established based on large clinical trials. However, at the same time it simplifies the general treatment optimization problem that needs to be solved on the per-patient basis, because the only adjustable parameter is the interval between drug doses. This simplicity is important in the clinic, because in most of the cases there are no robust frameworks to handle larger complexity of additional drug dose optimization problem.
In recent years, some theoretical inroads have been made to design treatment protocols that depart from the MTD paradigm and held the premise to be more effective in increasing patient survival, such as adaptive therapy. Concept of adaptive therapy is currently being investigated using various theoretical mathematical frameworks that are necessary to establish robust adaptive drug dosage protocols. In many cases the mathematical formulation of the problem consists of ordinary differential equations (ODEs) as they give the advantage of some analytical tractability and there are many existing numerical solvers that can be utilized. The search for the optimal treatment is based on either analytical approaches, such as optimal control theory, or brute force exploration of the possible treatment options space. The latter is obviously easier to implement, but is burdened with high computational cost. In a typical scenario optimal treatment schedule is searched for average (nominal) values of model parameters and no uncertainties in the patient-specific parameters are considered. It is conceivable, however, that you can come up with two different treatment protocols that for a given set of parameters result in the same tumor burden at a specified time point, but one is more sensitive to parameters perturbations. Thus, a formal assessment of the uncertainty in treatment outcome under the uncertainty in parameters values should be a part of any treatment exploration study. In this post I will show how to increase computational speed when attempting to asses distribution of treatment outcomes related to uncertainty in ODE model parameters. Presented code is written in MATLAB, but the underlying idea is valid for any other programming language.
Let us consider a simple ODE model that could be used for adaptive therapy investigations. We describe temporal evolution of two populations (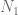

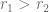


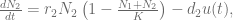
where 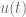

where 


Let us assume that we have already established the optimal drug administration protocol and we want to asses how the treatment will perform under different perturbations in parameters values.
First we need a function that for a given set of parameters returns the total size of the population (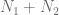
function PopEnd = solveModel( init, params, treatment, Tmax ) %%INPUT %init - 2x1 vector defining initial sizes of both populations [N_1; N_2] %params - structure with model parameters %treatment - moments in which drug is applied (t_i) %Tmax - simulation time %%OUTPUT %PopEnd - final popultion size (N_1+N_2) PopEnd = init; T = [0 treatment.t Tmax]; for i = 2:length(T) %solve in each inter-dose interval sol = ode45(@model,[T(i-1) T(i)],PopEnd); PopEnd = sol.y(:,end); %take as initial condition last known population size end PopEnd = sum(PopEnd); %N_1+N_2 %definition of model equations function y = model(t,x) y = zeros(2,1); %calculating current drug concentration u = params.D*exp(-params.clr*t)*sum(exp(params.clr*(treatment.t(treatment.t<t)))); %evaluating right hand side y(1) = params.r1*x(1)*(1-(x(1)+x(2))/params.K)-params.d1*u*x(1); y(2) = params.r2*x(2)*(1-(x(1)+x(2))/params.K)-params.d2*u*x(2); end end
We will use the above function to calculate population size after the end of treatment for large set of randomly pertubed nominal parameters values. In the following examples we will perturb parameter values uniformly by up to 10%.
Basic for loop approach
The most basic approach is to solve the model 
N = 1000; %number of trials treatment.t = [1 3 5 7 9 11 13]; %treatment schedule init = [10^5; 10^3]; %initial condition Tmax = 15; %simulation endpoint PopEnd = zeros(1,N); %vector with final population sizes for i = 1:N %perturbing parameters up to 10% params.r1 = 0.17*(1+(rand()-0.5)/5); params.r2 = 0.12*(1+(rand()-0.5)/5); params.d1 = 0.54*(1+(rand()-0.5)/5); params.d2 = 0.24*(1+(rand()-0.5)/5); params.K = 10^7*(1+(rand()-0.5)/5); params.D = 0.25; params.clr = 0.2*(1+(rand()-0.5)/5); %solving the model PopEnd(i) = solveModel( init, params, treatment, Tmax ); end
In the generated histogram of the final population size (see the plot below) we see that there is substantial amount of variation in treatment outcome.

Calculation of the above histogram for N = 1000 trials took about 7 seconds giving about 140 solutions per second.
The first idea to speed up the computation for larger N would be to use multiple CPUs and spread the for loop among them. There is, however, a better way that utilizes properly the CPU architecture.
Using single ODE solver invocation
Modern CPUs can perform operations on arrays and thus, perform many operations simultaneously. In case of small (low-dimensional) ODE systems numerical solvers can’t utilize that feature effectively as the computation of the next step consider only few variables at a time. However, in our case we can simply rewrite the problem of multiple solution of low-dimensional ODE system to single solution of large ODE system. Namely we can write the function calculating the solution in such a way that ith set of randomly generated parameters correspond to and 2i and 2i+1 equations in the large ODE system. In other words we feed the solver with all N sets of parameters and generate set of 2*N equations to be solved simultaneously.
function PopEnd = solveModelMult( init, params, treatment, Tmax ) PopEnd = init; %initial population T = [0 treatment.t Tmax]; for i = 2:length(T) sol = ode45(@model,[T(i-1) T(i)],PopEnd); PopEnd = sol.y(:,end); end PopEnd = sum(reshape(PopEnd,2,[]))'; function y = model(t,x) y = zeros(size(x)); if any(treatment.t<t) u = params.D.*exp(-params.clr*t).*sum(exp(bsxfun(@times,params.clr,treatment.t(treatment.t<t))),2); else u = 0; end %size(u) y(1:2:end) = params.r1.*x(1:2:end).*(1-(x(1:2:end)+x(2:2:end))./params.K)-params.d1.*u.*x(1:2:end); y(2:2:end) = params.r2.*x(2:2:end).*(1-(x(1:2:end)+x(2:2:end))./params.K)-params.d2.*u.*x(2:2:end); end end
Thus, in the main script we don’t need to use for loop and we just generate all N sets of random parameters.
%initial condition init = repmat([10^5; 10^3],N,1); Tmax = 60; %simulation endpoint tic params.r1 = 0.17*(1+(rand(N,1)-0.5)/6); params.r2 = 0.12*(1+(rand(N,1)-0.5)/6); params.d1 = 0.54*(1+(rand(N,1)-0.5)/6); params.d2 = 0.24*(1+(rand(N,1)-0.5)/6); params.K = 10^7*(1+(rand(N,1)-0.5)/6); params.D = 0.75*(1+(rand(N,1)-0.5)/6); params.clr = 0.2*(1+(rand(N,1)-0.5)/6); PopEnd = solveModelMult( init, params, treatment, Tmax ); t = toc();
The above code calculated N = 1000 solutions in about 0.2 seconds, which gives about 45x speed-up compared to the basic for loop approach. To check the validity of the single solver invocation approach we can compare resulting histograms.

For larger values of N we can obtain speed-up of up to 140 times when using single solver invocation approach instead of for loops, see the plot below. Of course both approaches can be parallelized and utilize all CPUs present in the system. However, parallelization of the single solver approach makes sense only for very large values of N, because for smaller N communication overhead becomes a major speed compromising factor.


Nicely explained. I would like to use these equations. How do you prefer they are cited, this page or do you have a publication you prefer?
LikeLike
Thanks. Feel free to use those equations without any citation – I’m glad that you found them interesting and you’re willing to do something about them. I guess that you have already way more data to feed the equations than I’ll ever have…
LikeLike
Thank you!
LikeLike